论文阅读:基于图像的深度学习识别医学诊断和可治疗疾病
发表在 Cell 2018.2.22
Paper: Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning
About:《Cell》为一份同行评审科学期刊,主要发表生命科学领域中的最新研究发现。《Cell》刊登过许多重大的生命科学研究进展,与《Nature》和《Science》并列,是全世界最权威的学术杂志之一。
前言,这篇文章主要讲了点啥
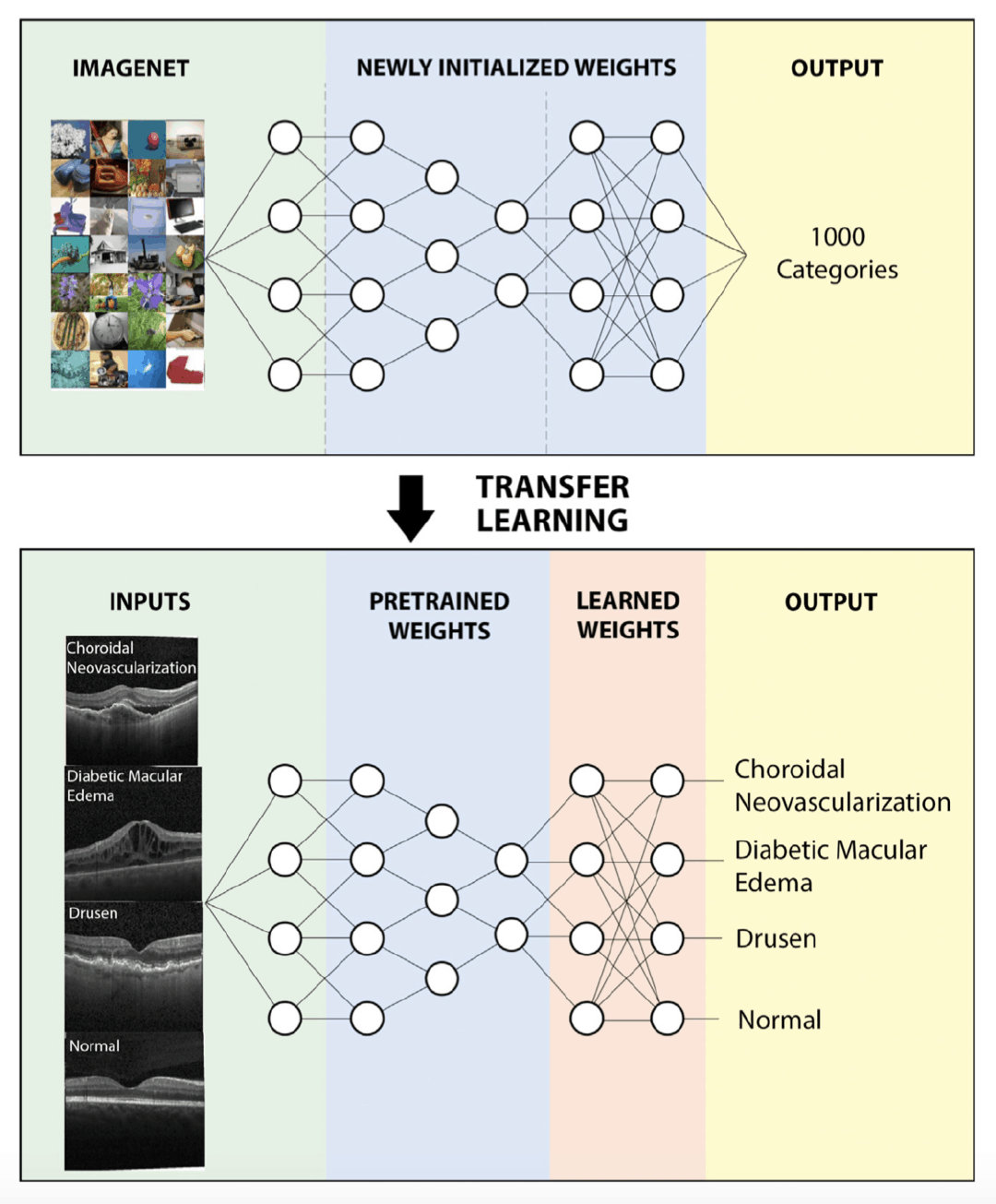
- 使用迁移学习技术开发了一个深度学习模型
- 模型能有效地分类黄斑变性和糖尿病视网膜病变的图像,取得了很高的分类精度
- 模型和人类专家进行比较,模型决策好于一些人类专家
- 模型有潜力在医疗影像中得到普遍应用,发挥较大作用
Summary
- 用于医学成像的临床决策支持算法的实施面临可靠性和可解释性的挑战。
- 在这里,我们建立了一个基于深度学习框架的诊断工具,用于筛查患有常见可治疗的致盲性视网膜疾病的患者。
- 我们的框架利用迁移学习,即使用传统方法的一小部分数据训练神经网络。
- 将这种方法应用于光学相干断层扫描图像的数据集,我们证明了性能与人类专家在分类年龄相关性黄斑变性和糖尿病性黄斑水肿方面的性能相当。
- 我们还通过突出显示神经网络识别的区域,提供更加透明和可解释的诊断。
- 我们进一步证明了我们的AI系统用于使用胸部X射线图像诊断小儿肺炎的一般适用性。该工具可以最终有助于加速这些可治疗病症的诊断和转诊,从而促进早期治疗,从而改善临床结果。
Introduction
AI 具有彻底改变疾病诊断和管理的潜力,因为可以完成对人类专家来说困难的分类任务,以及快速查看大量图像。尽管有潜力,但AI的临床可解释性和可行的准备仍然具有挑战性。
回顾传统图像分析方法和深度学习方法
以前用于分类图像分析的传统算法方法依赖于(1)手工制作的对象分割,其次是(2)使用统计分类器或针对每类对象特定设计的浅层神经机器学习分类器来识别每个分割对象,最后(3)分类图像(Goldbaum等,1996)。创建和重新定义多个分类需要许多技术人员和大量时间并且计算成本高(Chaudhuri等,1989; Hoover和Goldbaum,2003; Hoover等,2000)。
CNN 层的发展使图像分类和检测图像中的对象的能力得到了显着提高。使用多个卷积层在图像上进行卷积运算来构造每个层内的图像的抽象表示,产生的特征图用作下一层的输入。这种架构使得以像素形式处理图像作为输入并将所需的分类作为输出成为可能,取代了先前图像分析的多步骤方法。
介绍迁移学习(Transfer Learning)
解决给定域中缺少数据的一种方法,是利用来自类似域的数据,这种技术称为迁移学习。转移学习通过使用前馈方法来训练已经优化以识别图像中常见结构的较低级别的权重,而不是不是训练一个完全空白的网络,并通过反向传播重新训练高层的权重,这样,模型可以识别特定类别的图像(例如眼睛图像)的特征,并且训练速度快,样本显着减少,计算量降低。
这篇文章干了啥
在本文中,我们寻求开发一种有效的迁移学习算法来处理医学图像,以提供每个图像中关键病理的准确和及时的诊断。 我们主要针对视网膜的光学相干断层扫描(OCT)图像,但也在一组儿科胸部X光片中进行了测试,以验证在多种成像模式中的普遍适用性。
网络结构
网络结构很简单,就是文章开头的那张图。具体来说,使用了在 ImageNet 数据集(包含 1000 个类别)上预训练的 Inception V3 网络
- 将预训练模型在新的 OCT 图像数据集上训练,显着提高了精确度,缩短训练时间
- 训练方法是:冻结卷积层,重建和训练最后一层全连接层,使用随机初始化
Transfer Learning Methods
- Tensorflow 框架,采用在 ImageNet 数据集上预训练的 Inception V3 架构。
- 训练过程包括用加载的预训练权重初始化卷积层和重新训练最终的 softmax 层以从头开始识别新定义的分类。
- 卷积层被冻结并用作固定特征提取器。卷积“瓶颈”(bottlenecks)是每个训练和测试图像在通过我们模型的冻结层之后的值,并且由于卷积权重未更新,因此最初计算并存储这些值以减少冗余过程并加速训练。
- 然后,新初始化的网络将图像瓶颈作为输入并重新训练以对我们的特定类别进行分类。
- 通过使用反向传播解冻和更新我们的医学图像上的预训练权重来“微调”卷积层的尝试倾向于由于过度拟合而降低模型性能。
- 训练环境和一些细节
- Intel Xeon CPU * 2,Ubuntu 16.04,NVIDIA GTX 1080 8GB GPU,256G RAM
- 学习率为 0.001 的 Adam Optimizer,1,000 张图像作为一个batch
- 所有类的训练都进行了 10,000 个step或 100 个 epoch
Results
通过迁移学习得到的模型应用于诊断视网膜OCT图像。
为什么 OCT 影像对于视网膜疾病至关重要
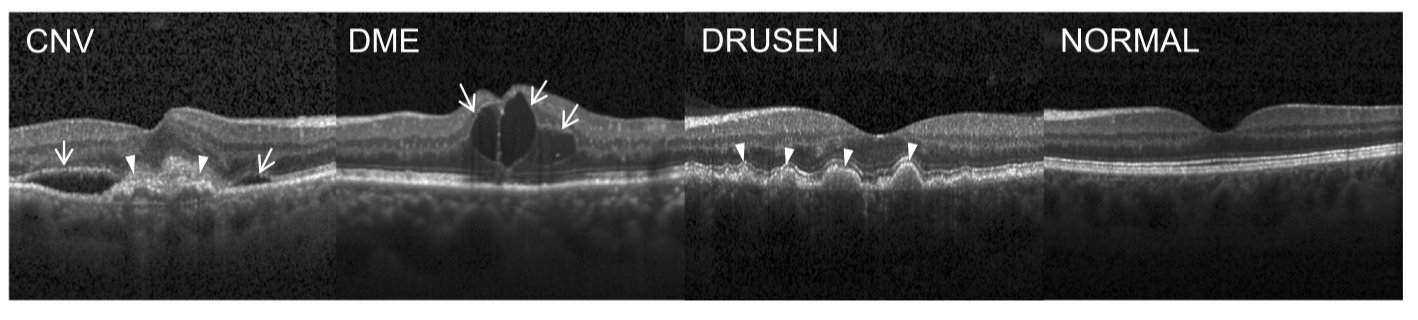
- 光谱频域OCT(Spectral-domain OCT)使用光来捕获视网膜的高分辨率体内光学横截面,其可以组装成活体视网膜组织的三维图像。它已成为最常用的医疗影像之一,每年在全球范围内会进行大约3000万次OCT扫描(Swanson和Fujimoto,2017)。
- OCT成像现在是在世界范围内的一个谨慎标准(standard of care),用于指导诊断和治疗失明的主要起因——年龄相关性黄斑变性(AMD)和糖尿病性黄斑水肿。
- 在美国,近1000万人患有AMD,每年有超过 200,000 人患有脉络膜新生血管,这是一种严重致盲的晚期AMD(Ferrara,2010,Friedman等,2004,Wong等,2014)。
- 此外,近75万40岁或以上的人患有糖尿病性黄斑水肿(Varma等,2014),这是一种视力威胁形式的糖尿病视网膜病变,涉及视网膜中央积液。由于人口老龄化和全球糖尿病流行,这些疾病的患病率可能会随着时间的推移而进一步增加。
- 幸运的是,抗血管内皮生长因子(抗VEGF)药物的出现和广泛应用彻底改变了渗出性视网膜疾病的治疗方法(Kaiser等,2007,Ferrara,2010),使患者能够保持可用视力和生活质量。
- 因此,OCT对于指导抗VEGF治疗的施用至关重要,因为可以提供视网膜病理学的清晰截面表示,允许个体视网膜层的可视化,而这在人眼或彩色眼底摄影的临床检查中是不可能提供的。
数据集
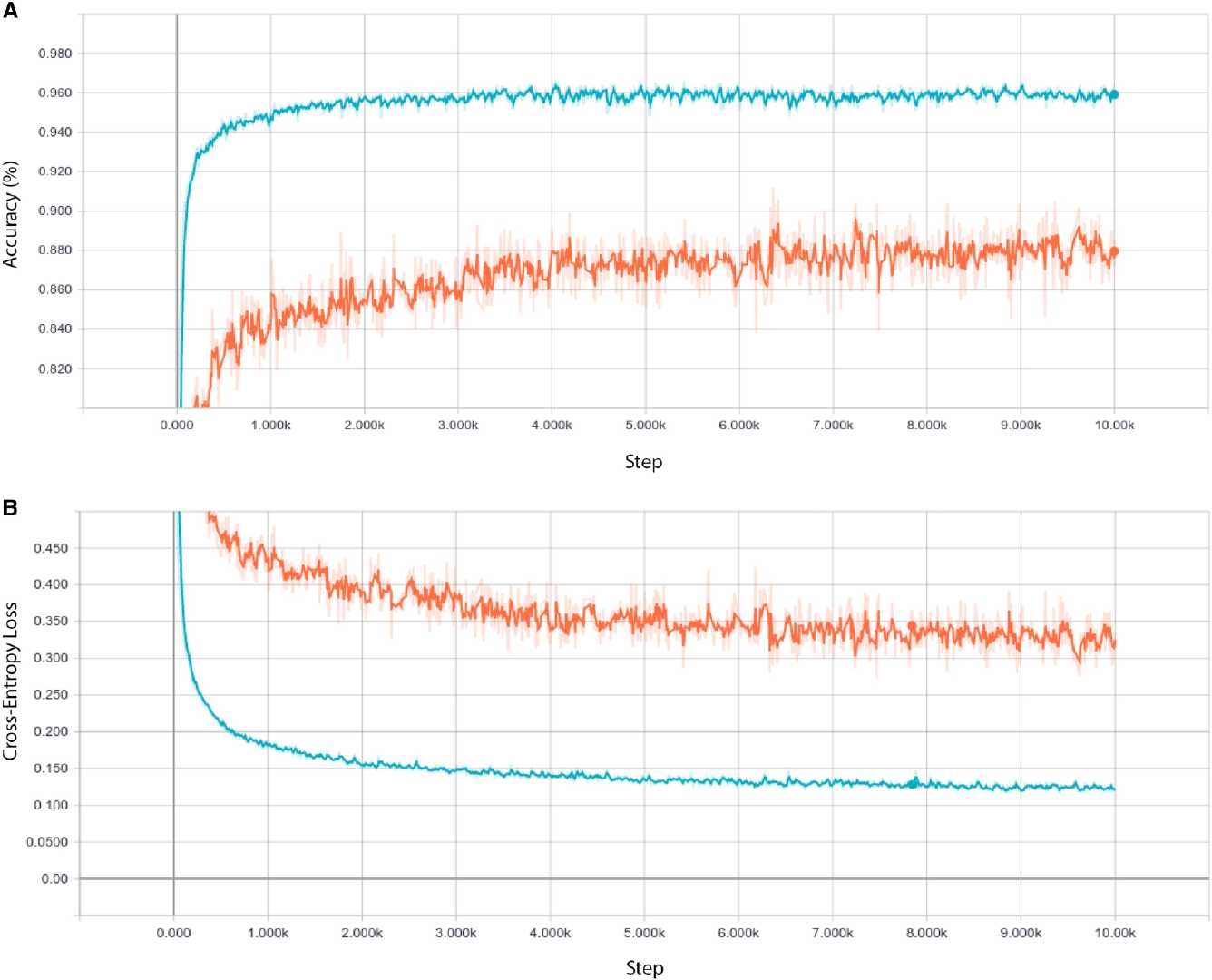 使用来自 4,686 名患者的 108,312 张图像(37,206例脉络膜新生血管,11,349例糖尿病性黄斑水肿,8,617例玻璃膜疣,51,140例正常)训练,来自633名患者的1,000张图像(每个类别250张)进行测试。 训练了 100 个 epoch 之后,由于准确度(图A)和交叉熵损失(图B)没有进一步改进,因此停止了训练。
使用来自 4,686 名患者的 108,312 张图像(37,206例脉络膜新生血管,11,349例糖尿病性黄斑水肿,8,617例玻璃膜疣,51,140例正常)训练,来自633名患者的1,000张图像(每个类别250张)进行测试。 训练了 100 个 epoch 之后,由于准确度(图A)和交叉熵损失(图B)没有进一步改进,因此停止了训练。
Performance of the Model
评估方式:诊断最常见的致盲性视网膜疾病,OCT 图像被分为四类:脉络膜新生血管,糖尿病性黄斑水肿,玻璃疣,正常。
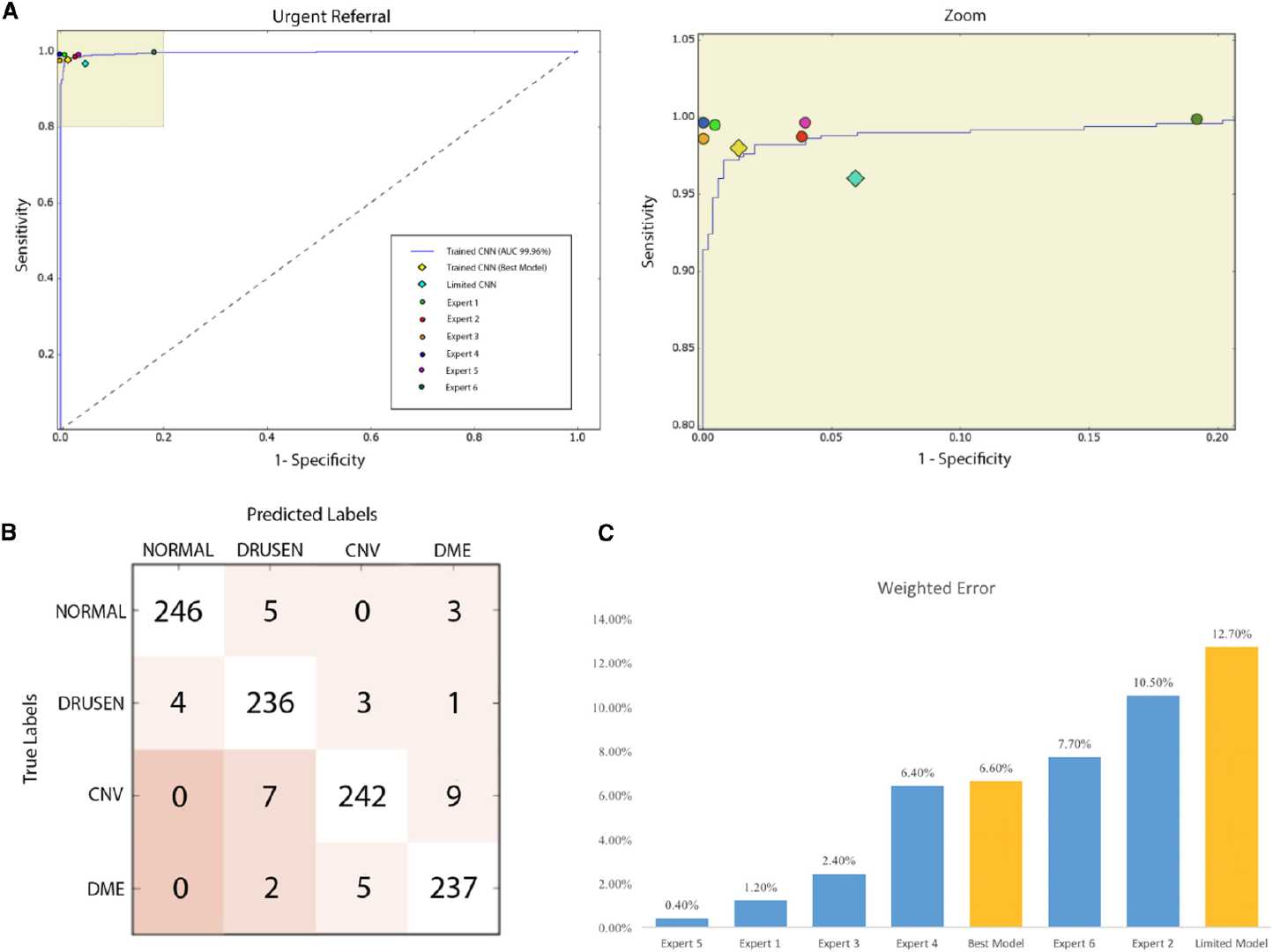
在四分类测试中,实现了准确度 96.6%,灵敏度 97.8%,特异性 97.4%,加权误差 6.6%。ROC曲线评估模型区分紧急转诊(定义为脉络膜新生血管或糖尿病性黄斑水肿)与不紧急转诊(玻璃疣和正常)的能力(下同),AUC为99.9%。(这个性能表现真的是很惊人了)
本文还训练了一个“有限模型”,即四个类别的每个只随机选择了 1000 张图像进行训练,最终实现准确度 93.4%,灵敏度 96.6%,特异性 94.0%,加权误差 12.7%,AUC 98.8%。可见大数据集对模型性能的影响还是很显著的。
另外,训练的几个二元分类模型,测试中表现都非常不错:
- 区分脉络膜新生血管/糖尿病性黄斑水肿/玻璃疣图像和正常图像(即患病和健康):准确度 100.0%,灵敏度 100.0%,特异性 100.0%。 AUC 100.0%。
- 区分糖尿病性黄斑水肿图像与正常图像的分类器:准确度 98.2%,灵敏度 96.8%,特异性 99.6%,AUC 99.87%。
- 区分玻璃疣图像与正常图像的分类器: 99.0%,灵敏度 98.0%,特异性 99.2%。 AUC 99.96%。
Comparison of the Model with Human Experts
模型性能好是一方面,但是用于辅助诊断的模型,肯定还是要和人类专家比一比。
- 采用测试集:来自 633 名患者的1,000 张图像的独立测试集
- 如何比较:在学术眼科中心具有重要临床经验的六位专家,被指示仅使用患者的OCT图像对每个测试患者做出转诊决定。区分需要紧急转诊的患者(脉络膜新生血管或糖尿病性黄斑水肿)和不紧急患者,绘制ROC曲线,这样就可以比较了。
-
比较结果:在训练模型的ROC曲线上绘制专家的敏感性和特异性,并且在95%置信区间内确定模型与人类专家之间通过似然比测量的诊断性能差异在统计学上相似。
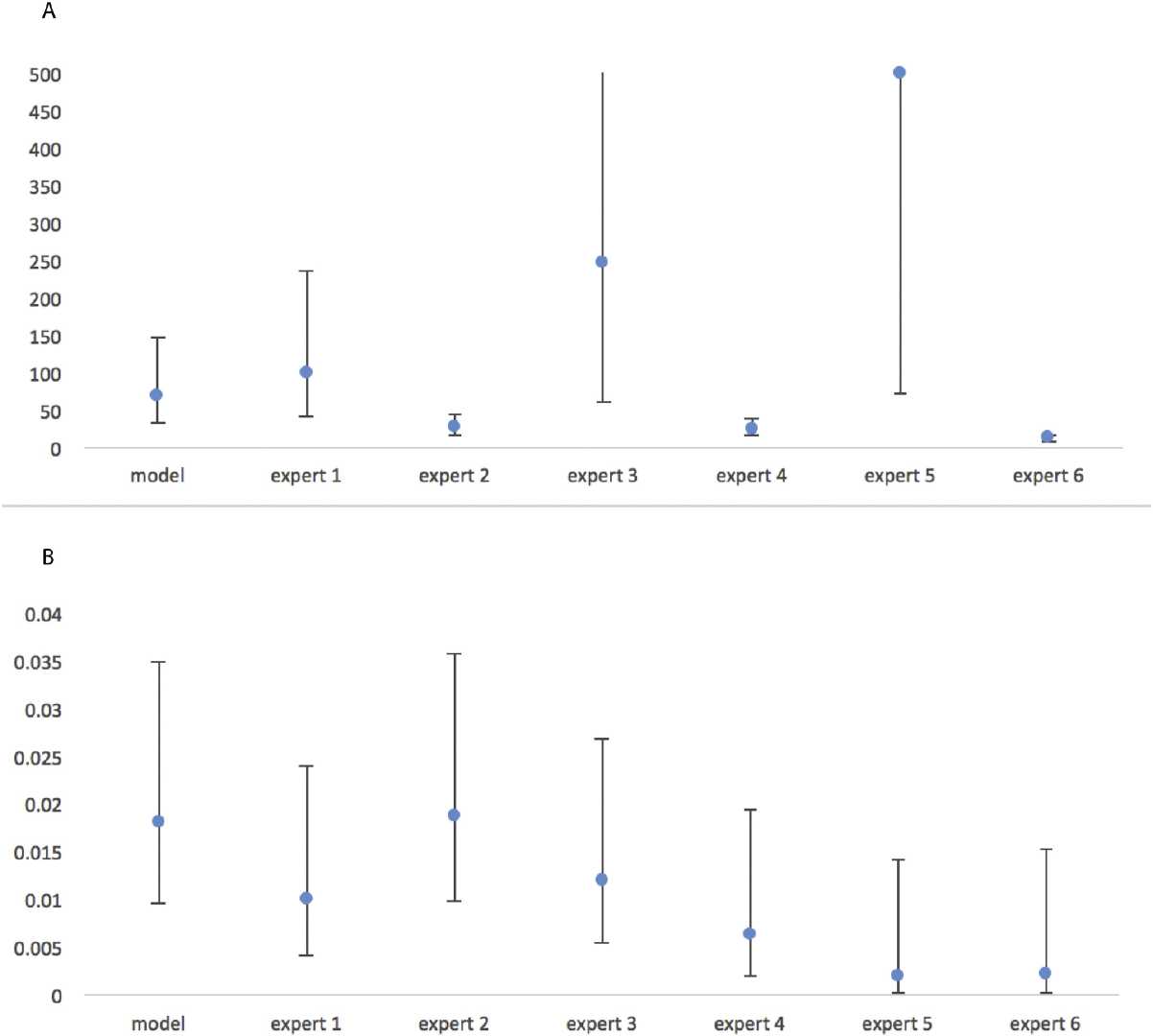
然而,纯误差率并不能准确反映错误的转诊决定可能对个体患者的结果产生的影响。我们都知道:假阳性可能会让实际未患病的患者承受不必要的诊断痛苦和压力;而假阴性的后果更加严重,会导致实际患病的患者无法得到及时转诊治疗。
为了解决这些问题,本文在模型评估和专家测试期间引入了加权误差评分(简单的说,就是惩罚假阴性的严重分类错误)。通过将这些惩罚点分配给模型和专家做出的每个决策,文章计算了每个的平均误差。
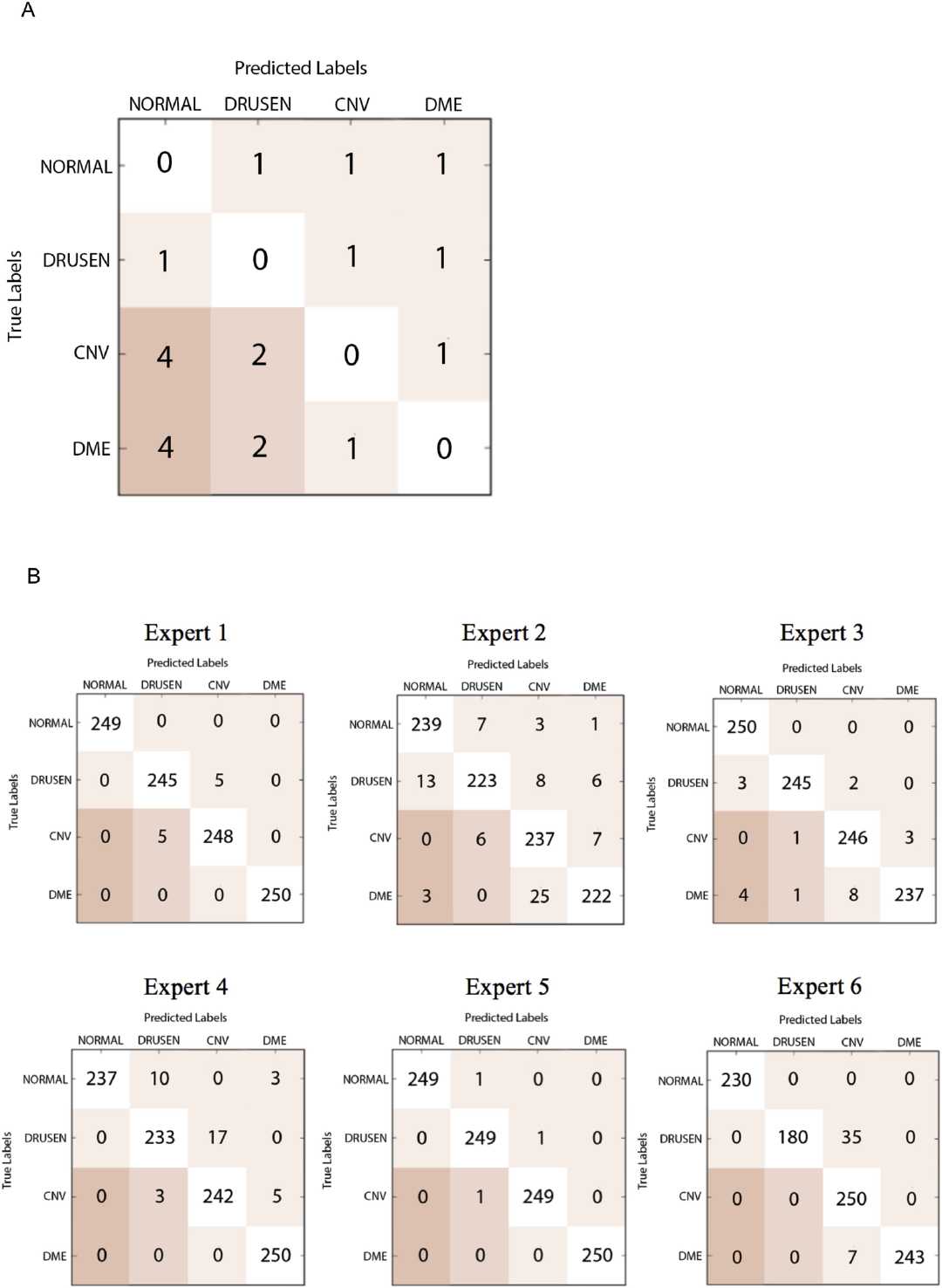
在该加权误差系统下,最佳的卷积神经网络模型得分为6.6%。专家的加权误差范围为0.4%至10.5%,平均加权误差为4.8%。每个专家关于其预测标签与真实标签的相关性的精确分解在图S4B中被描述为混淆矩阵。如图,基于该加权尺度和ROC曲线,最佳模型优于一些人类专家。
后记 by Piddnad
读完这篇文章,自己也感到非常震撼。文中的方法取得了令人振奋的结果,证明如今处理医疗影像深度学习模型确实达到了用于辅助诊断的性能,AI + 医疗的前景充满希望。
有什么想法,留个评论吧: