Paper Reading: On the Detection of Digital Face Manipulation
On the Detection of Digital Face Manipulation
- Publication:CVPR 2020
- Authors:Hao Dang, Feng Liu, Joel Stehouwer, Xiaoming Liu, Anil K. Jain
- Affiliation:Michigan State University
- Paper:🔗
关键点
- 采用多任务学习改进伪造监测
- 使用注意力机制改进分类性能,注意力层重点突出被篡改脸部区域。
- 注意力层采用两种方式生成:直接回归或是 PCA 方式
- 构建一个新的综合假脸数据集 DFFD
- 提出一种新的定位精度度量方式
1 Proposed Method
1.1 Motivation

- 在分类 backbone 中添加一个 attention layer(本文说该方法可以在任何 backbone 中集成)
-
生成的 attention map 上每个像素的值,对应其感受野在输入图像中是被篡改区域的概率(如下图,real 的图片我们希望 attention map 是全 0;部分被篡改则希望篡改区域激活值大;完全生成的假脸则对应全 1 的 map)

- 相当于增加一个辅助监督信号,显示约束网络去关注被篡改区域
1.2 Attention-base Layer
本文提出的 attention map 有两种生成方法:
- MAM(Manipulation Appearance Model)
其实就是一种 PCA 的方法,假设任何表示修改区域的 map 都可以表示为一组 map 原型的线性组合:
\(\mathbf{M}_{a t t}=\overline{\mathbf{M}}+\mathbf{A} \cdot \alpha\)
$\overline{\mathbf{M}}$ 和 $\mathbf{A}$ 分别是 mean map 和 basic map,如下图。这样就只需要用一个卷积层和一个全连接层去回归一个权值$\alpha$。

- Regression:使用若干卷积层直接回归
1.3 Loss Functions
最终训练损失:分类损失 + 注意力图损失,使用超参数 $\lambda$ 控制权重。
\[\mathcal{L}=\mathcal{L}_{\text {classifier }}+\lambda * \mathcal{L}_{\text {map }}\]$ L_{map} $ 的三种定义方式:
- supervised:训练样本有 ground-truth mask 的情况
- weakly supervised:主要思想为真图像驱动整个 map 为 0,假图像最大激活值应该足够大(大于0.75)。
- unsupervised:$\lambda = 0$,此时在不监督 map 的情况下训练网络
2 Diverse Fake Face Dataset
TLDR
- 包含了之前几个大型 deepfake dataset(例如FF++),还包括了一些新生成的 fake face images
- 299,039 images(58,703 real & 240,336 fake)+ 4000 video clips(1000 real & 3000 fake, from FF++)
数据集构成:
- Real Face:FFHQ,CelebA
- Fake Face:涵盖 4 种主要 face manipulate 方法
- Face reenactment:FaceForensics++、Face2Face
- Face replacement: FaceForensics++、FaceSwap、Deepfake、Deep Face Lab
- Face editing:FaceAPP(from FFHQ),StarGAN(from CelebA)
- Face Synthesis:PGGAN,StyleGAN
3 Experiments
3.1 Ablation Study
注意力图带来的增益
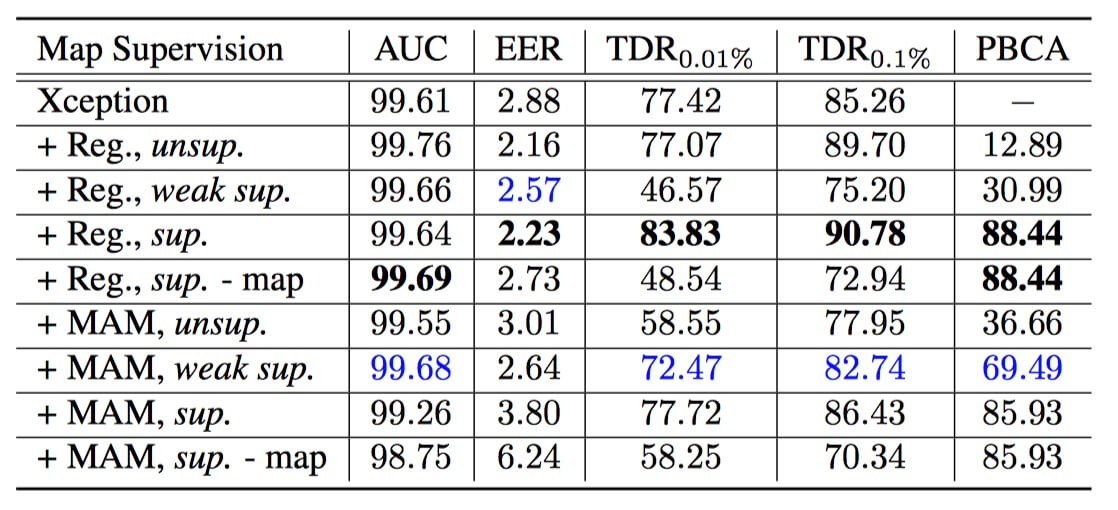
采用 XceptionNet 作为 backbone,在 middle flow 的 Block 4 和 Block 5 之间插入注意力层。
实验结果:有监督学习在检测和定位准确率(PBCA)上都优于弱监督和无监督学习。另外,对比两种 attention map 生成方法,回归方法在有监督的情况下具有更好的效果;而基于MAM的方法在弱监督和无监督情况下更优,因为 MAM 对 map 估计提供了强约束。
不同 backbone 对比实验

在 DFFD 数据集上使用 Xception 和 VGG16 对比,发现在大和深的网络(Xception)中,使用直接回归的注意力层更好;小的网络(VGG16)中 MAM 方式的注意力层效果更好。
文章给出的解释是:因为更深的网络具有更大的参数空间,因此网络可以直接回归 attention map;而对于更小更浅的网络,直接生成的 attention map 会引起参数空间的争用(contention)。而MAM 提供的先验约束减少了这种竞争(只需要拟合 10 个参数),因此提高了性能。
3.2 Foregery Detection Results
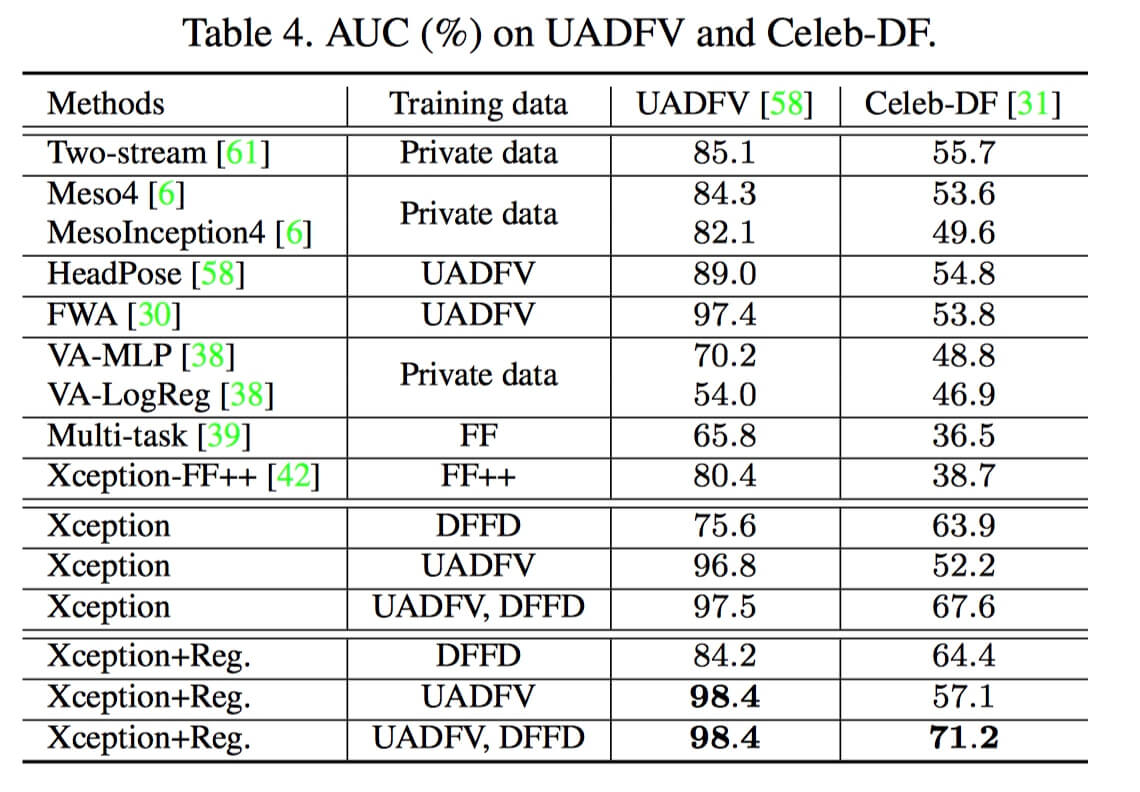
在 UADFV 和 Celeb-DF 上和之前的方法进行比较,证明了注意力机制到来的提升,以及数据多样性对模型的影响(相同网络结构采用 DFFD 训练比用 UADFV 性能要好很多)。
3.3 Manipulation Localization Results
这部分没有细看,大致是分析网络生成的 attention map 对比 ground-truth mask 的 localization 性能分析,还提出了一个新的定位度量方式 IINC,比直接算余弦相似度、IoU 或者 PBCA(Pixel-wise Binary Classification Accuracy)更加可靠。
4 Conclusion
最近好几篇 face forgery detection 方向的工作都提出了通过添加各种各样的 mask 来改善检测性能的方法。其核心思想都是增加额外的监督信号,因而隐式或显式地约束网络去重点关注被篡改区域。这种多任务学习的思想还是非常值得借鉴的。
这篇文章个人认为也存在着一些缺点,首先是 ground-truth mask 的生成问题,在没有 source image 的情况下难以生成对应 fake image 的 mask,这就为注意力层的监督训练带来困难;另一方面,PCA 的方法确实对小模型有所提升(提供额外先验约束),但也存在局限性,因为性能受计算出的 mean map 和 basic map 的限制,应该要和测试数据分布足够相似才能 work。
有什么想法,留个评论吧: