A Brief Review of Few-shot Object Detection Papers
好久好久没有写 blog 了,今晚借着修评论服务的机会(虽然好像并没修好- -(0401 edit:修好了!)),贴一篇自己之前写的小样本目标检测(Few-shot Object Detection)领域的论文笔记,拯救一下我这尘封多年的博客。
另外,自己整理的一个 FSOD Paper List 也在 GitHub 上收获了 100 个 star,对这一领域有兴趣的同学可以看一看。
LSTD:A Low-Shot Transfer Detector for Object Detection【finetune-based】(AAAI 2018)🔗
- Motivation:在小样本上做迁移学习,很难消除分类和检测之间的任务差异,而且容易产生过拟合
- 主要贡献:模型结构上整合了SSD和Faster RCNN;提出两个用于微调阶段的新的正则损失TK和BD,TK在候选目标中transfer源域标签知识,BD用目标的GTbox来做特征图额外监督。
- 模型结构:

- 微调loss:分类回归+正则化损失,两个正则化损失LBD和LTK计算方法如下图
- BD就是取出中间特征图,用GTBox做一个mask,不在mask内的部分做L2正则化,这样就能抑制背景区域的相应,增加目标区域处的响应;
- TK就是,用源域训练好的分类器对目标数据集中propasal进行分类(结果肯定不对),微调时在目标域分类器的基础上再新增一个和源域类别相同的源域分类器,该源分类器随机初始化,结果和之前的源域分类器结果计算交叉熵损失(类似蒸馏),相当于用源数据集预训练结果来引导目标分类器训练。(新增梯度流)

(大概是公认的开山之作)Feature Reweighting【model-based】(ICCV 2019)🔗
- Motivation:小样本检测
- 主要贡献:提出 reweighting 方法引入 few-shot object detection
- 核心思想:用 support 的 feature 对输入 feature 进行 reweight
- 模型结构:
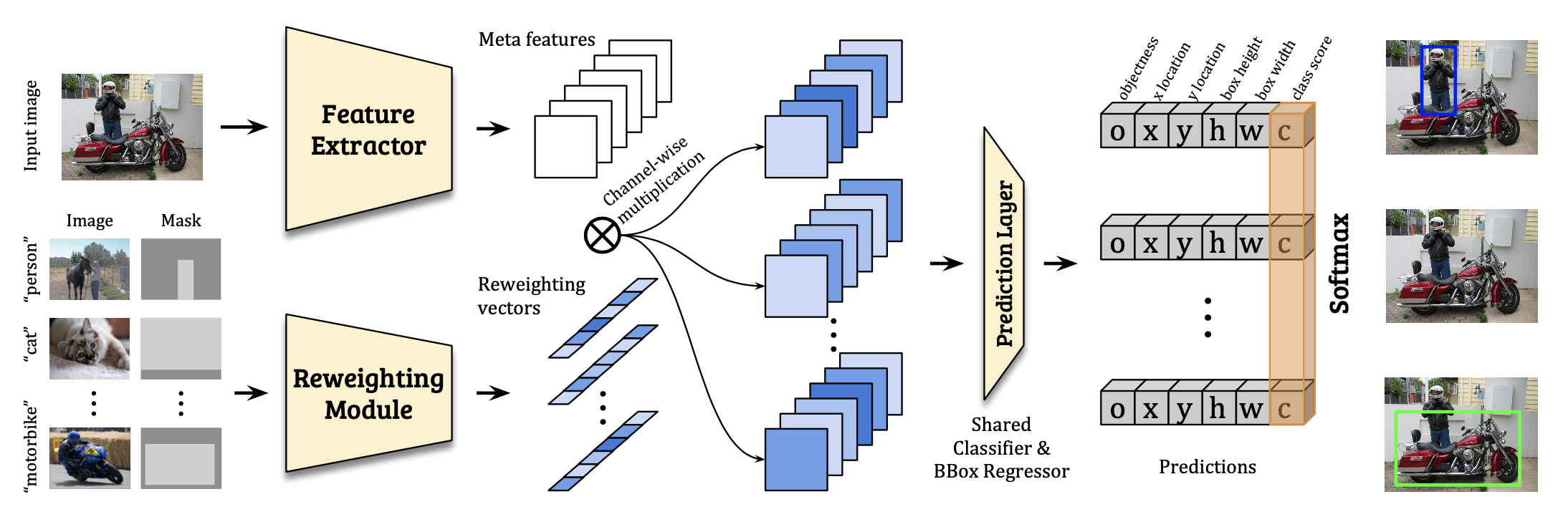
- 实现细节:
- 基于 YOLOv2 网络,backbone(DarkNet-19)作为元特征提取器
- 训练时用一个额外的 Reweighting Module 处理 support image+一个 0-1 mask,得到对应类别 vector,对 backbone 得到的特征做通道维度加权
- 测试时把全部 support 过 Reweighting Module 得到的 vectors 做平均,减少计算量
- 2-phase learning scheme:
- base training:只用base类,每次 N support & 1 query
- few-shot tuning:base + novel,都是 k-shot
- 消融实验:
- Reweight哪一层(最后一层最好)
- 分类损失函数(softmax最好)
- support的输入形式(原图+mask最好)
Meta-RCNN【model-based】(ICCV 2019)🔗
- 主要贡献:meta-learning,整合ROI特征(类似将Reweighting那篇思路搬到两阶段检测网络)
- 核心思想:增加一个PRN,得到class attentive vectors,然后对pooled ROI feature加权
- 模型结构:

- 实现细节:
- 训练阶段:meta-train meta-test
FsDet【finetune-based】(ICML 2020)🔗
- 主要贡献:two-stage fine-tuning approach;修订评估指标,包括bAP和nAP
- 核心思想:train Faster R-CNN + fine-tuning the last layers on a balanced set
- 模型结构:
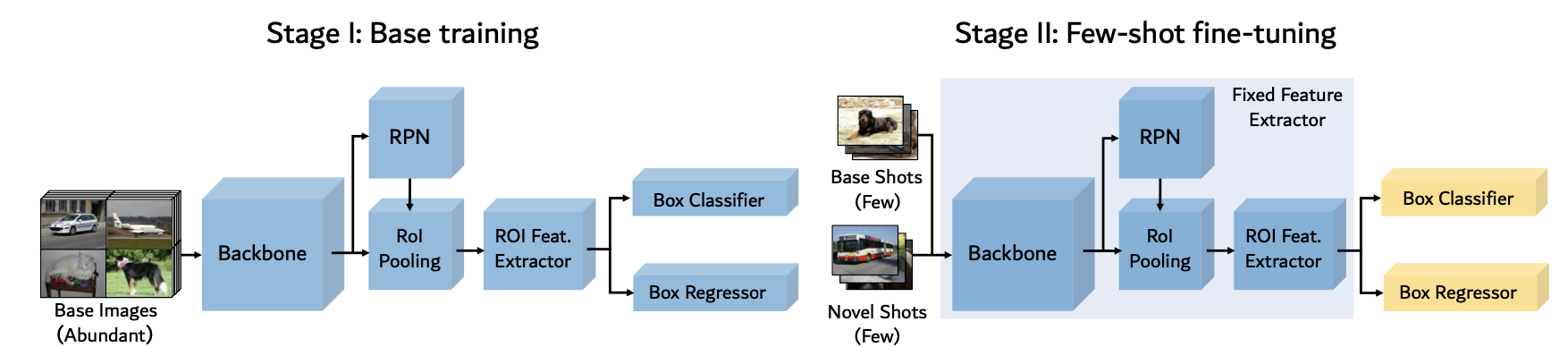
- 实现细节:
- 两阶段 Finetune(TFA)
- 使用 base class 正常训练
- 使用 base 和 novel class 的 k-shot 平衡集 finetune 检测头
- 为什么只tune最后一层:直观地说,backbone和RPN的特征是类不可知的。因此,从基类中学习到的特性很可能会转移到新的类中,而不需要进一步的参数更新。(感觉有点扯)
- 余弦分类器:
- 用一个不带 bias 的 fc 实现,对输入 x 和 fc 都做一下 normalize 即可
- 实例级特征归一化:文章发现与FC-based分类器相比,实例级特征归一化用于基于余弦相似度的分类有助于减少类内方差,提高novel类的检测精度和更少减少检测base类的准确度,特别是在训练样本数量很少时。
- 两阶段 Finetune(TFA)
AttentionRPN【metric-based】(CVPR 2020)🔗
- 主要贡献:一种通用的无需微调的fsod模型;一个大型fsod数据集
- 核心思想:Attention-RPN、Multi-Relation Detector、2-way contrastive training strategy
- 模型结构:
- 实现细节
- Attention-RPN:
 support feature 平均池化到 1x1xc ,然后作为卷积核,在 query image上进行 depth-wise 卷积得到attention feature map G之后接一个正常的3X3卷积,有点类似于Separable Convolution(一般的separable convolution先depth-wise再channel-wise,只不过一般的channel wise卷积核大小为1x1)
support feature 平均池化到 1x1xc ,然后作为卷积核,在 query image上进行 depth-wise 卷积得到attention feature map G之后接一个正常的3X3卷积,有点类似于Separable Convolution(一般的separable convolution先depth-wise再channel-wise,只不过一般的channel wise卷积核大小为1x1) - Multi-Relation Detector:
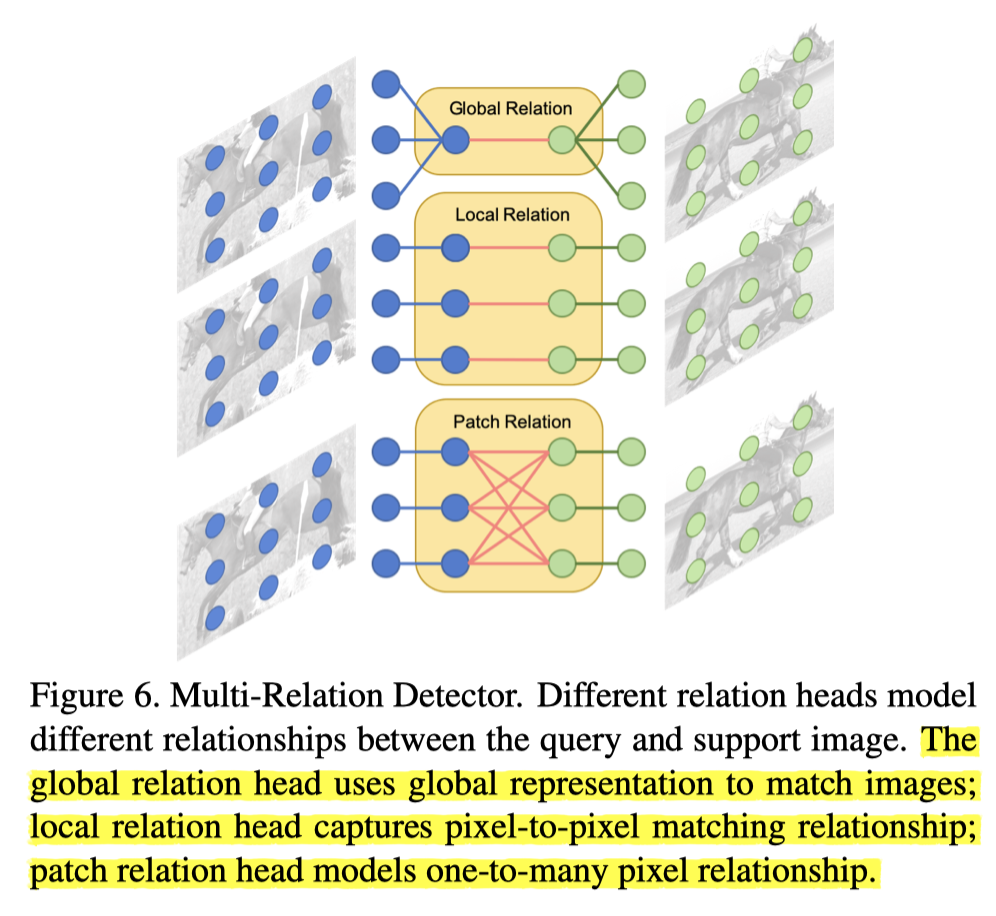 输入是两部分的 roi-pooling 得到的特征图,分别来自 support image 和 query image
三个结构并行计算相似度,也就是三个结构分别会对query image中每一个ROI计算出一个相似度,这时候每一个ROI区域就有三个置信度,将三个置信度结合起来(也许是取平均),得到这个ROI最终的置信度。这时就可以通过阈值卡,留下置信度阈值之上的框从而得到最终的预测结果。
输入是两部分的 roi-pooling 得到的特征图,分别来自 support image 和 query image
三个结构并行计算相似度,也就是三个结构分别会对query image中每一个ROI计算出一个相似度,这时候每一个ROI区域就有三个置信度,将三个置信度结合起来(也许是取平均),得到这个ROI最终的置信度。这时就可以通过阈值卡,留下置信度阈值之上的框从而得到最终的预测结果。
- Global Relation:假设送过来的ROI特征图大小固定为7x7xC。这时候我们有两个ROI特征图,一个叫S来自support,一个叫Q来自query(当然query中可能有多个roi特征图,这里只以一个为例)。首先将这两个特征图concatenate,这时候就变成了7x7x2C,经过一次全局平均池化变成1x1x2C,相当于获取了全局信息。这时候就可以通过一系列全连接操作输出得到一个数值(从2C降维到1),该数值就是两ROI特征图相似性。
- Local Relation: 先对两个ROI特征图分别用weight-share的1x1卷积进行channel-wise操作,然后再进行类似于Attention RPN的操作,区别在于support image的ROI特征图不需要全局池化到1x1,而是直接以7x7的大小作为一个卷积核在query image的ROI特征图上进行channel-wise卷积,变成1x1xC,最后同样使用fc层得到预测相似度。
- Patch Relation:首先将两个ROI特征图进行concatenate,变成7x7x2C,然后经过一系列结构如下图所示。注意图中的卷积结构后面都会跟一个RELU用来获得非线性,并且pooling和卷积结构都是stride=1以及padding=0,这样在经过这些操作之后,ROI特征图的大小会变为1x1x2C,后面接一个全连接层用来获得相似度,除了相似度之外,还并行接了一个全连接层,产生bounding box predictions。 在这个模块中,ReLU之后的所有卷积层和池化层都有零填充,从而将feature map的大小从7×7缩小到1×1。额外使用一个fc层来生成匹配分数和一个单独的fc层来生成边界框预测。
- Attention-RPN:
Multi-Scale Positive Sample Refinement for Few-Shot Object Detection【finetune-based】(ECCV 2020)🔗
- Motivation:在全监督训练的时候,各种大小的目标都有不少,所以训练完之后检测各种大小的目标性能都还行,但对于few shot的设定,每一类的实例较少,导致scale数量少,而且和真实的scale的分布相差甚远,所以scale就成了问题。
- 主要贡献:在常规模型上加了一个 Multi-Scale Positive Sample Refinement Branch,直接用 GT object 做图像金字塔,然后送入 FPN,取跟输入图像大小一致的 feature map 送进检测头,计算分类损失
- 模型结构:
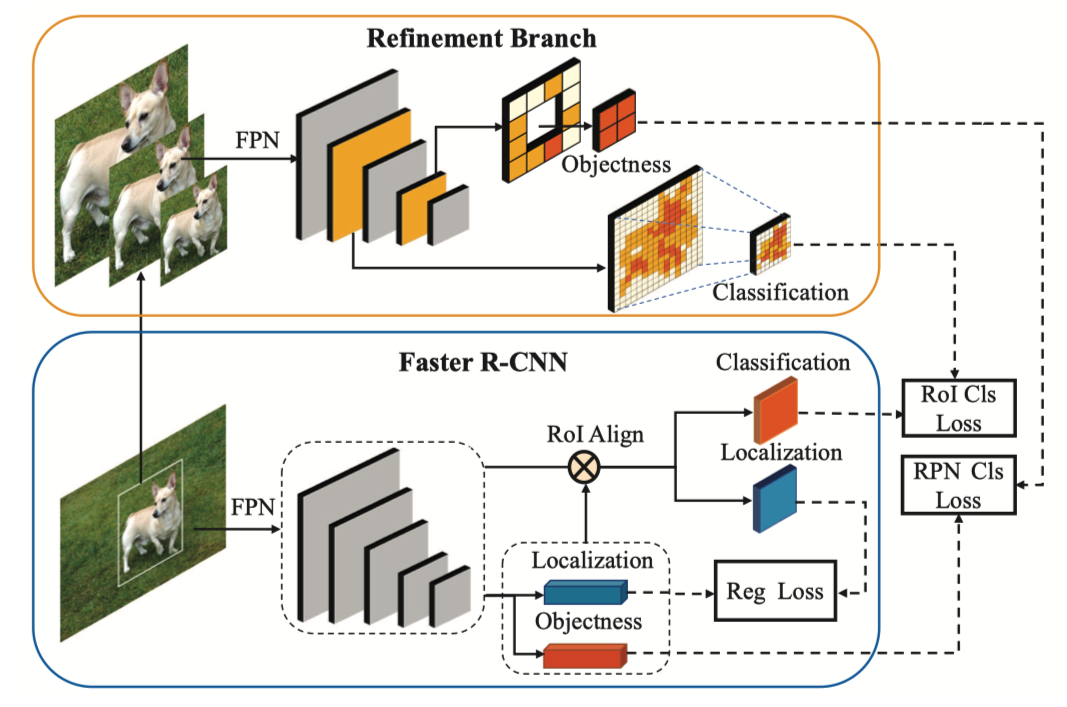
FSCE【finetune-based + metric-based】(CVPR 2021)🔗
- Motivation:一个观察:在基于微调的FSOD模型中,分类比定位更容易出错。因此,通过拉近类内距离,拉开类间距离的想法来提高分类准确率。
- 主要贡献:更好的baselibne,新增一个 contractive head,利用对比学习改善分类
- 模型结构:

- 实现细节:
- strong baseline:(VOC split1 10-shot ,能提 5.4 个点 (5/7.4))
- finetune 时 unfroze RPN(这个在我自己的实验中也证实了)
- 加倍 RPN 的 NMS 保留的 proposal 数量(RPN.POST_NMS_TOPK_TRAIN:1000->2000)(原因:finetune 时,RPN 其实有一些比较好的 novel class 的 positive anchor,但是得分比较低所以被 NMS 干掉了,因此改变 RPN 的 NMS 阈值把他们救回来)
- 减半 head 里面用于损失计算的 proposal 数量(ROI_HEADS.BATCH_SIZE_PER_IMAGE:512->256,但是按理说应该再把 POSITIVE_FRACTION 改成0.5才对。128:384 -> 64:192))
- Contrastive Proposal Encoding (CPE) Loss(+2个点 (2/7.4))
- 添加一个 head,输入 N 个 1024 位 proposal vector,先经过一个全连接变成 128 维,然后计算对比损失
- 对比损失用 RoI 0.7 去卡,具体怎么做没仔细看
- strong baseline:(VOC split1 10-shot ,能提 5.4 个点 (5/7.4))
- 代码细节:其实提出的 CPE 作用不大:在 VOC 能提点但是提的不如 strong baseline;COCO 上提不了点,所以压根没用到(see: https://github.com/MegviiDetection/FSCE/issues/20)
Retentive-RCNN【finetune-based】(CVPR 2021)🔗
- Motivation:大多数以前的工作仅仅关注于新类的性能,检测所有类是至关重要的,因此需要监测模型在学习新的概念时不忘记旧的先验知识。
- 主要贡献:在使用微调提升新类别性能的基础上保证基类不掉点。
- 模型结构:

- 实现细节:
- Re-detector:两个检测头,一个使用固定的 base 模型参数,一个用于 finetune,同时添加一致性正则损失保证 finetune 时的头和原来的基类头输出相似的基类得分。(这个一致性损失没有做消融实验比较加和不加的效果,感觉对提点作用应该不会太大?)
- Bias-Balanced RPN:两个RPN,base RPN 参数固定,finetuned RPN 只微调 objectness 分支,然后两个的 objectness 分支输出求 max 作为最终输出。
- 训练策略:只解冻三层:finetuned RPN 的 objectness 分支,novel 检测头的分类和回归层最后一层。
- 推理:RPN 输出 proposal 同时输入两个头,然后一起做 NMS,base 检测头如果通过了 NMS 阈值则分数+0.1。
DeFRCN【finetune-based】(ICCV 2021)🔗
- Motivation:Faster R-CNN 的 RPN 是 class-agnostic 的,而 RCNN 是 class-relevant 的,所以两个结构有冲突;另一方面,RCNN 的分类需要 translation-invariant 特征,而回归需要 translation-covariant 特征。这些目标不匹配的矛盾可能会损伤性能。
- 主要贡献:提出 GDL 模块和 PCB 模块分别实现 Faster RCNN 的结构解耦和任务解耦,大幅提点实现 sota。
- 模型结构:

- 实现细节:
- Gradient Decoupled Layer:前向传播时做一个仿射变换(线性变换层),反向传播时对梯度进行一个缩放。其实就是让 RPN 和 RCNN 的输入不一样,学习率也不一样。
- Prototypical Calibration Block:一个离线的模块,只有evaluation的时候用到了。包含一个预训练分类器
- 使用支持集的 gt 生成的一个原型库,包含 C 个 prototype
- 用一个预训练好分类器对 Proposal 进行分类,和每个 prototype 计算余弦相似度,最后和 RCNN 分类分数加权得出最终分数。
有什么想法,留个评论吧: